Using the Java Kinesis Client Library (KCL) with localstack
/ / Reading Time: 10 MinuteWait wait, hear me out: Consuming a multi-sharded kinesis stream by implementing the Java Kinesis Client Library, and to top it off, use localstack to run our code locally. Interested? Great, let’s go!
Only interested in the result? Here is the Github Repository.
Kinesis Data Streams
Kinesis Data Streams is one of the many, many, managed services provided by Amazon Web Services (AWS). Kinesis streams can be sharded based on a partition key, allowing multiple consumers to each consume a specific shard in parallel.
Sharding is a way of scaling the consumers on a stream, while still maintaining the order of the messages based on the partition key.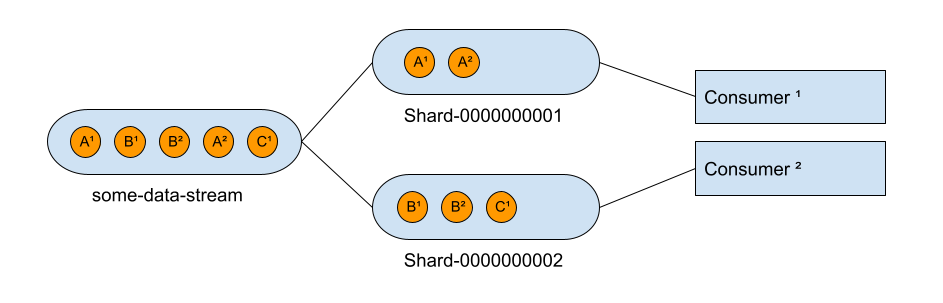
With this example, you can see that message A-1 can be handled in parallel of message B-1, but messages A-1 and A-2 are always processed in order by the same consumer.
Configuring localstack
Usually we would setup the Kinesis Stream using CloudFormation, Terraform, or the AWS Console itself, but since we want to be able to test our code locally we will use localstack instead.
Localstack is “a fully functional local cloud stack”, which means it gives us a local implementation of almost every AWS service. Luckily we don’t need all the services provided by Amazon, but only Kinesis (obviously), DynamoDB and Cloudwatch.
We need DynamoDB as the Kinesis Client Library (KCL) uses a DynamoDB table to store the checkpoints of all shards. Checkpoints can be considered the state of the client, containing which application has the lease on which shard, and at which sequencenumber the consumer is currently processing the data.
We need CloudWatch as the Kinesis Client Library (KCL) provides metrics to monitor our application.
Setup
1 | $ pip install localstack |
Running
1 | $ SERVICES=kinesis,dynambodb,cloudwatch localstack start -d |
Awesome, we can now interact with our local AWS services by using the awslocal cli and create our Kinesis stream.
1 | $ awslocal kinesis create-stream --stream-name some-data-stream --shard-count 2 |
And that’s all we need, we have our localstack environment and we have our Kinesis data stream with two shards, time to get our hands dirty and build some actual code!
Setting up the Kinesis Client Library
Dependencies
Let’s start with the build.gradle file which lists all the dependencies we will need.
1 | plugins { |
Configuration
We’ll have to instruct our application which Kinesis Data Stream to consume, and in which region this stream lives. We can default the region to US_EAST_1 since that is the default region used by localstack.
1 | package com.vreijsen.consumer.configuration; |
Our application.yaml can then contain the following.
1 | kinesis: |
Since we’ll be using three AWS services, we have to define a client bean for each one of them.
1 |
|
You can see we annotated the class with @Profile("localstack") as it overrides the endpoints on the clients to point to our localstack environment running on our own machine.
We can define the same class but without the endpoint overrides and annotate it with @Profile("!localstack") to connect to the actual AWS cloud when not running with the localstack profile.
Kinesis Scheduler
The KinesisScheduler is the heart of the library and will do all our Kinesis magic. We can provide the clients that we just setup, but most importantly provide a ShardRecordProcessor which will be created for every shard the application holds the lease of.
When implementing the ShardRecordProcessor we have a few methods that we can override to adjust the behaviour to our specific needs.
The most important method to override is the processRecords(ProcessRecordsInput input) as it is the entry point for all data coming in from that shard. For our demo, we’ll just log every record that comes in.
1 |
|
Alright now that we have a ShardRecordProcessor we can initialize the Kinesis Scheduler.
1 |
|
With this scheduler we can now create our deamon thread and start consuming!
1 |
|
Ofcourse to be able to consume data we’ll first need to send some data to the Kinesis stream. Keep in mind the Data property should be Base64 encoded.
1 | awslocal kinesis put-records --stream-name some-data-stream --records Data=SGVsbG8gV29ybGQ=,PartitionKey=partition-1 |
When we run our application using the localstack profile we should see the following logs.
1 | INFO : Received Kinesis message: KinesisClientRecord(sequenceNumber=49626058596308151669577377721366592164732241681909284866, approximateArrivalTimestamp=2022-01-23T12:24:27.560Z, data=java.nio.HeapByteBufferR[pos=0 lim=11 cap=11], partitionKey=partition-1, encryptionType=NONE, subSequenceNumber=0, explicitHashKey=null, aggregated=false, schema=null). |
Hooray! We’ve successfully implemented the Kinesis Client Library, and made it run locally using our own localstack environment 🎉
Want to see the full application? Here is the Github Repository.